“天河E级智能计算开放创新平台”与“天河天元大模型”在世界智能大会期间正式发布
5月19日,作为世界智能大会重要组成部分,世界智能科技创新合作峰会在国家会展中心(天津)举行。会上,国家超级计算天津中心正式发布“天河E级智能计算开放创新平台”和“天河天元大模型”。受到人民日报、新华社、中国日报、科技日报等媒体广泛关注和报道。

习近平总书记指出,人工智能是新一轮科技革命和产业变革的重要驱动力量,加快发展新一代人工智能是事关我国能否抓住新一轮科技革命和产业变革机遇的战略问题。近期以来,以ChatGPT为代表的生成式智能的发布和应用,开启人工智能发展的新阶段,在世界范围内引起了广泛的关注和强烈反响。
为了助力人工智能创新,促进数字经济高质量发展,充分发挥超算在算力方面的优势,推动国产异构超级计算机平台在人工智能应用开发和服务领域中的应用,国家超级计算天津中心立足国产超级算力和智能算力,打造“天河E级智能计算开放创新平台”,研发训练“天河天元大模型”,并于2023年5月19日正式发布。此次发布核心是,立足国产超级算力和智能算力,收集构建中文大数据集,研发训练自主生成式基础大模型。在生成式智能的大算力、大数据、大模型上走出一条完整的信创路线,系统支撑中国生成式智能创新发展。

突破人类“知力”的生成式AI基础大模型
AI大模型是基于海量多源数据打造的预训练模型,是对原有算法模型的技术升级和产品迭代,用户可通过开源或开放API/工具等形式进行模型零样本/小样本数据学习,以实现更优的识别、理解、决策、生成效果和更低成本的开发部署方案。预训练大模型在基于海量数据的自监督学习阶段完成了“通识”教育,再借助“预训练+精调”等模式,在共享参数的情况下,根据具体应用场景的特性,用少量数据进行相应微调,即可高水平完成任务。
传统概念里,我们总是把人的能力分成体力和脑力,但是面对现在生成式通用人工智能挑战,我们必须来反思,现在的通用智能到底给我们人类带来什么变革,它是否真的已经超越人类?通常,我们会把脑力等同于智力;在《大学》开篇里有一句“物有本末,事有终始,知所先后,则近道”,这正是“知道”的出处;在我们最早的文字起源中,“智”从“知”,但是随着认知的不断演化,“智”和“知”出现了分化。今天,对“知”更强调的是掌握知识,而“智”则是“机智、心智、超越知之上的抽象推演等能力”。所以,在新的背景下,可以将脑力分成“知力”与“智力”,今天,生成式大模型的突破,实际上在突破和挑战我们的“知力”,但是人类的随机应变能力、想象能力,还有我们不断抽象推演基础上的再抽象、再推演能力,都是现在的大模型无法挑战和突破的。但正是对“知力”的突破,使在大模型基础上的生成式AI成为新的变革社会生产力和生产关系的存在。
算力成为人工智能发展的核心驱动
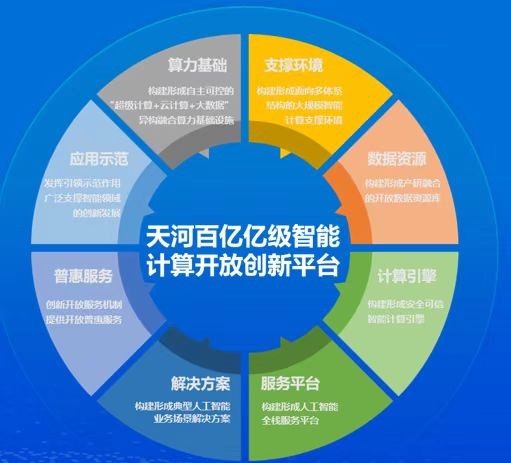
天河E级超智算力平台
大模型发端于自然语言处理领域,以谷歌的BERT、OpenAI的GPT和百度文心大模型为代表,参数规模逐步提升至千亿、万亿,同时用于训练的数据量级也显著提升,带来了模型能力的提高。同时这也代表了算力消耗的指数级上升。在这个新一轮科技革命和产业变革的关键节点,人工智能、大数据对我们的巨大影响,让我们更加深刻的认识到,算力正在成为生产力发展的核心驱动。
而超级计算机可以说是算力中的战斗机,单体最强大算力的存在,同时由于超级计算机作为一个系统工程的超级大脑,每一代超级计算机都要完成从计算芯片升级、数据交换能力升级、系统级软件升级等突破后才能实现整机系统的突破,因此超级计算机研制能力成为体现国家信息技术创新能力,特别是算力发展的重要象征,是战略科技力量。天河超级计算机,从千万亿次,到亿亿次,十亿亿次,再到现在百亿亿次,不断挑战世界算力速度极限,而天津也依托天河新一代超级计算机的强大算力资源,成为算力赋能全国科技创新和产业发展的重镇。
在天河新一代超级计算系统中,我们设计实现了柔性体系架构,支持带来世界领先的双精度、单精度、半精度融合计算输出能力。在完成传统的高精度科学工程计算之外,构建基于自主E级算力体系架构的自主创新智能计算引擎,建设人工智能大规模训练与应用系统支撑环境。天河E级智能计算开放创新平台将带来突破百亿亿次的跨模态的超级计算算力,支撑传统的科学工程计算,并服务智能混合计算,打造全方位的算力赋能创新和数字经济高质量发展载体。

数据是人工智能发展的基石
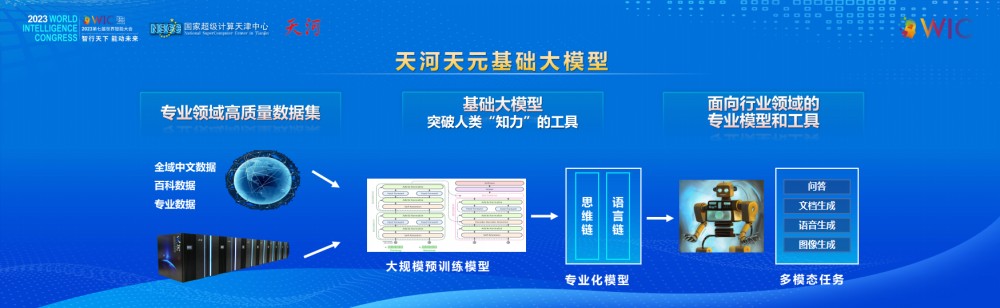
中文数据集支撑的天河天元大模型
数据是AI发展的基石,是产业智能化发展中最宝贵的资源。海量的数据,为人工智能自监督学习带来巨大助力。利用好爆发增长的海量数据,将会是企业充分挖掘数据红利、构建数字经济下竞争壁垒的重要抓手。
众所周知,中文大语言模型的数据集非常稀缺。天津超算中心搜集整理了网页数据、各种开源训练数据、中文小说数据、古文数据、百科数据、新闻数据,以及专业领域的中医、医药、问诊、法律等多种数据集,训练数据集总token数达到~350 B,训练打造了自己的中文语言大模型—天河天元大模型。同时在持续训练和完善中,并在此基础上启动深度训练面向医疗、工业、法律等领域的专业模型。
未来大模型将带动新的产业和服务应用范式,在深度学习平台的支撑下将成为产业智能化基座。在人工智能统一底座上融合专家知识图谱,即可打造面向跨场景或行业服务的“元能力引擎”。该模式将进一步驱动各行各业的生产能力、生产效率从“量变到质变”,实现跨越式发展。跃升数字生产力,用好AI,将成为国家、行业、企业的核心竞争力。
面向行业深度应用
以超级算力与生成式AI打造行业专家
行业大模型就是在基础大模型上,进一步融合行业数据、知识以及专家经验,提升大模型对行业应用的适配性。预训练大模型增强了人工智能的通用性、泛化性,基于大模型通过零样本或小样本精调,就可实现在多种任务上的较好效果。大模型“预训练+精调”等模式带来了新的标准化AI研发范式,实现AI模型在更统一、简单的方式下规模化生产。这将会带来一场以通用人工智能为驱动力的“AI革命”。
将大模型作为产业智能化升级基座,用专业数据集,打造更贴合行业领域的智能化高水平“专家”。为行业赋能,推动行业升级,提升领域创新效率、行业生产效率,是人工智能驱动新一轮科技革命和产业变革的巨大力量。未来,以生成式AI为基座的产业链将成为智能化升级过程中可大规模复用的基础设施。在大模型通用性、泛化性以及降低人工智能应用门槛的优势推动下,人工智能也将会加快落地,形成新的机遇。
此次天河E级智能计算开放创新平台和天河天元大模型正式发布,体现了超级算力发展与生成式AI创新突破,为未来创造更多协同发展的可能。让国产创新基础上的“天河E级超智算力开放平台”、“天河天元大模型”赋能百业,赋能天津,赋能中国高质量发展。